
Hi! This is Kazushi from JADE K.K.
Tweets by KazushiNagayama twitter.com
5 years ago when I was a Googler, I wrote a blog article titled “Understanding Web Pages Better”. We announced that Google Search started to render web pages using JavaScript, which was really exciting news back then. Pages that weren’t previously indexable started to show up in the search results, improving the searchability of the web by a huge margin. We started by rendering a small part of the index and gradually scaled it up, finally letting us deprecate the longstanding AJAX crawling scheme.

5 years on, a lot of people now take it for granted that Google renders web pages by executing JavaScript. It has evolved a ton thanks to the hard work of great engineering teams at Google; it’s a result which I’m personally very proud of. However, unfortunately, it doesn’t mean that anyone can use JavaScript to create websites that rely on client-side rendering entirely, and expect Google to index all of their pages.
Recently, Martin Splitt from Google’s Webmaster Trends Analyst (WTA) team released an article titled Understand the JavaScript SEO basics, which provides a great explanation of how Google’s rendering processes are set up. I’ve refrained from talking publicly about these points after leaving Google, but now that Google has officially released information about the system in detail, there are a few quick comments I’d like to make about the setup.
tl;dr: full client-side rendering can still hinder the searchability of a site, especially for large-scale web services.
Why? The diagram by Martin is self-explanatory: rendering is designed to be an additional step before the actual indexing happens.
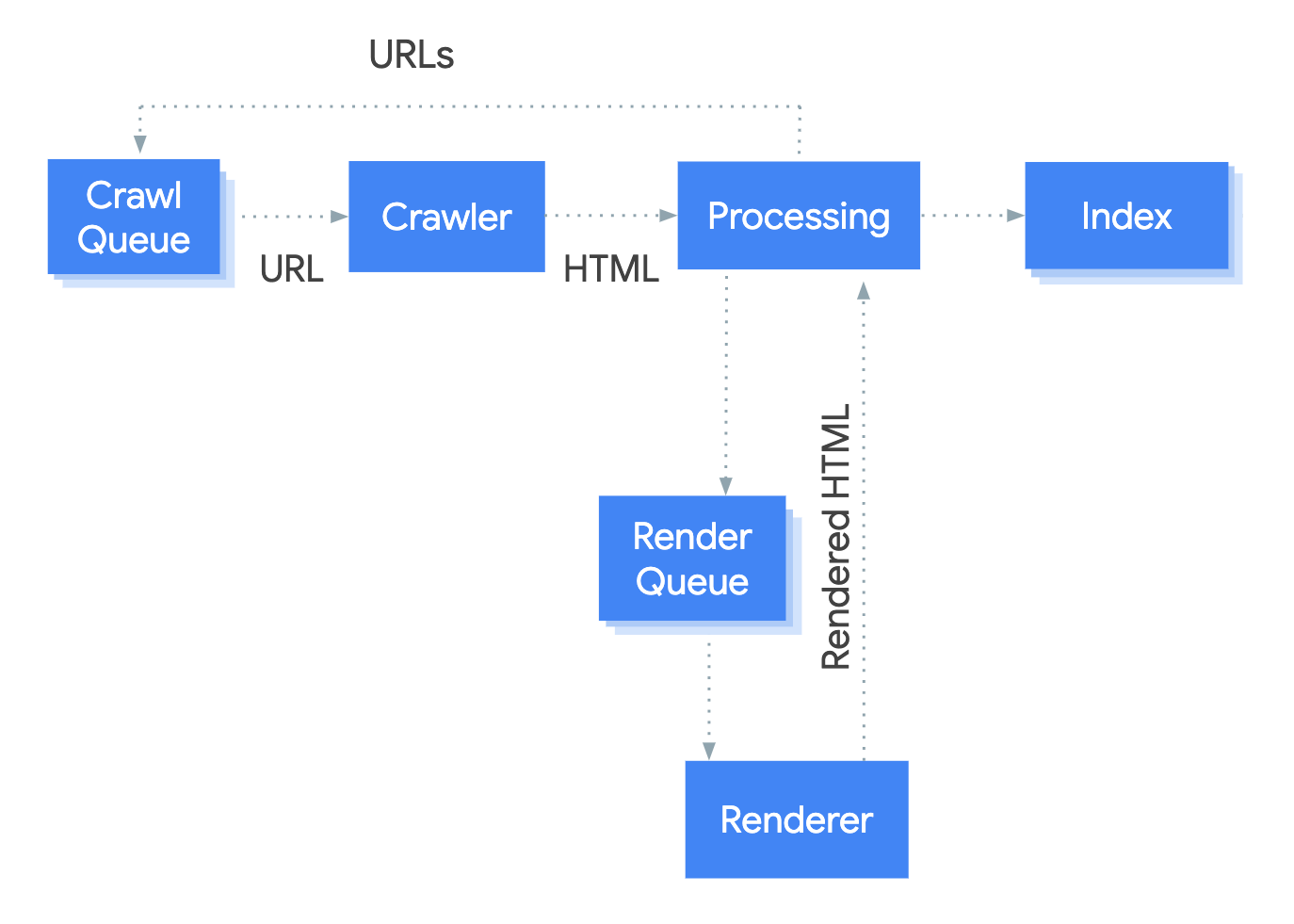
As the diagram suggests, if Google notices that a page needs to be rendered, it will be added to the Render Queue to wait for the Renderer to process it and return rendered HTML. Google needs to judge the importance of the page's content before actually seeing what the content is. Even though it hasn’t rendered the page yet, it needs to come up with a sophisticated guess of how much value will be added to the index by rendering the content.
There is a close structural resemblance of this rendering problem to the crawling problem. In crawling as well, Google needs to make an educated guess about the importance of the page it discovered on the web before actually completing the crawl.
What does this mean for webmasters? We should be aware that Render Budget exists, just like Crawl Budget.
Gary Illyes, also a Google WTA, wrote an article titled “What Crawl Budget Means for Googlebot” in 2017. It’s a really good article and you should go read it if you haven’t already. Put shortly, Google decides the crawl priority of pages based on site popularity, content freshness, and server resources.
In crawling, the biggest is bottleneck usually the server resource on the side of websites that are being crawled. Google needs to make good predictions on how much load the host can tolerate, and decide how fast it crawls the site, striking a good balance between user needs and update frequency. This is a very sophisticated system that the great crawl engineering teams have built, even though it receives little attention from external parties.
On the other hand, the biggest bottleneck in rendering is the server resources on the Google side. Of course, there are new resources like JavaScript and JSON files that Google needs to crawl, which will add to the ‘crawl budget’. However, while some of the resources can be cached to minimize the crawl, pages that needs rendering usually needs to be rendered from scratch every time. And even Google can’t use their computing resources freely to have an index with fully-rendered, fully-fresh pages from the entire Web.
Google needs to decide which pages to render, when, how much. And just like crawl budget, it uses signals to compute priorities. In this case, the most important ones are the popularity of the site, and the number of URLs that need rendering.
If a site is popular and needs a lot of rendering, then you’d assign more resources for rendering the site. If there’s no rendering needed, no resources are allocated. If there’s a website that needs a lot of rendering but is not very popular, Google will assign some resources to render some of the paged deemed important within the website. Sounds all natural, right?
Let’s apply this to a scenario where you’ve created a new single-page application that fully renders on the client side. You return templated HTML and send content separately in JSON files. How much render budget will you have assigned from Google? There’s a lot of cases where the site doesn’t have crawlable URLs (you need to give permanent URLs to states you want crawled!), but even if you did it right, it's quite difficult for Google to figure out how important your new site is for the users. Most likely, it’ll slowly give you budget to test the waters while trying to gather signals about your site. As a result, not all of your URLs will be indexed at a first pass, and it may take a very long time for it to be fully indexed.
“My site has been in the index for a long time and Google knows how popular it is”, you say? Does that mean that it’s OK to do a full revamp of the site to make it render client-side? No. If you’ve been returning HTML that doesn’t need a lot of rendering, then suddenly changed all of your URLs to render client-side, Google needs to recrawl AND render all URLs. Both crawl budget and render budget impacts your site negatively in this setup. As a result, it might take months, even over an year, to get all of your URLs to the index after the site revamp.
In conclusion: client-side rendering in large-scale websites is still unrealistic if you want your URLs to be indexed efficiently. The ideal setup is to just return plain HTML that doesn’t need any JavaScript execution. Rendering is an additional step that Google supports - but that means it’s forcing Google to make extra efforts to understand your content. It’s time- and resource-consuming, which can slow down the indexing process. If you implement dynamic-rendering, returning server-rendered content to Googlebot while making users render client-side, it will become easier for Google to process your site, but that also means you’re just making your servers do the work for Google.
In the end, returning static, simple HTML continues to be the speediest and most accurate if you want your site indexed fast, at a massive scale. Client-side rendering can hinder the performance of your website in the SERPS, especially for news sites that needs to be indexed fast, or large-scale web platforms that produce hundreds of thousands of new URLs every day.
Google has been working hard to recognise pages that use JavaScript, making it years ahead of other search engines in understanding today’s web. It’s working great even looking at it from an external perspective, up to mid-scale websites. It’s guaranteed to evolve even more, which I'm personally very excited about.
However, the current system isn’t perfect -- just like any engineered system. Where Google fails, the webmasters need to chime in for help from the other side. If your service is producing hundreds of thousands of URLs every day, then you probably want to pay attention to these details, and proceed with caution.
All participants of the web ecosystem can contribute to enable a world where information is delivered swiftly to the users that need it. Let’s keep building a better web, for a better world!